
Alibaba Cloud released the multimodal AI model Qwen2.5-Omni-7B, which supports text, image, audio and video processing, and achieves human-like interaction with 7 billion parameters. Open source promotes the universal application of AI.

Alibaba Cloud Qwen2.5-Omni
Technical architecture and core innovation
1. Thinker-Talker dual-core architecture
Qwen2.5-Omni-7B adopts a human-like dual-core collaborative design to simulate the brain’s “thinking-expression” mechanism:
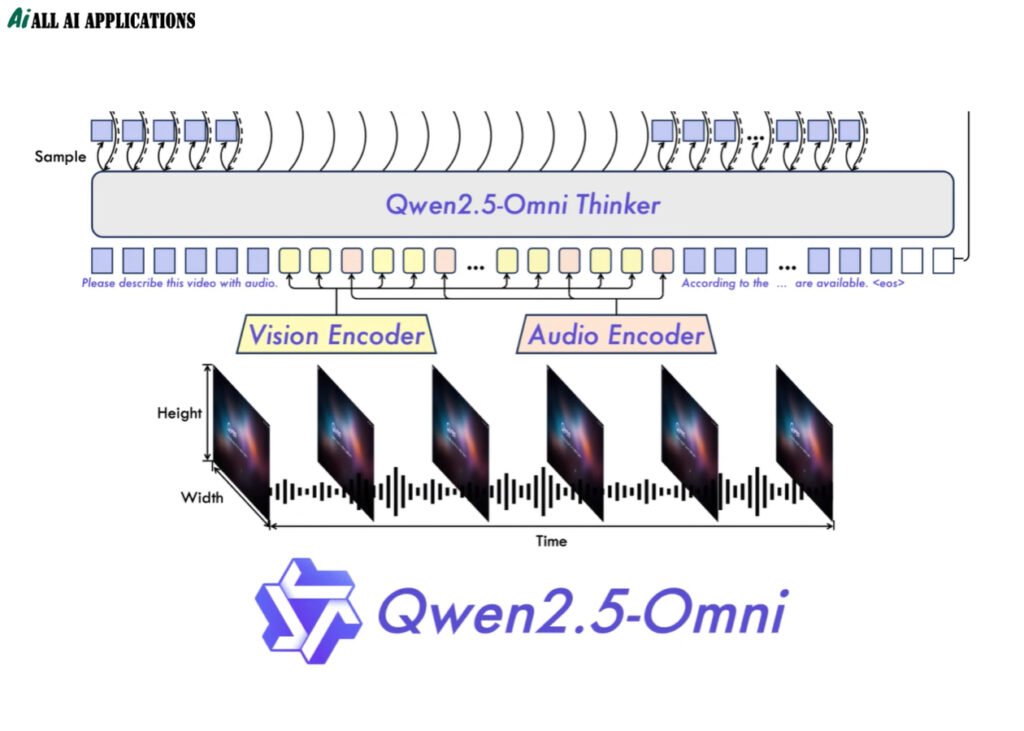
- Thinker: As the core processing module, it integrates multimodal encoders to extract text, image, audio, and video features, and generates high-level semantic representations and text content through Transformer decoders.
- Talker: Receives Thinker output in a streaming manner, uses a dual-track autoregressive Transformer decoder, synthesizes natural speech in real time, and shares historical context to ensure semantic consistency.
This architecture supports end-to-end training and reasoning, significantly reducing the latency and complexity of traditional multimodal models (such as ASR+NLP+TTS tandem).

Qwen2.5-Omni-7B AI model training
2. TMRoPE position encoding algorithm
To address the audio and video synchronization problem, the team proposed Time-aligned Multimodal Rotational Position Embedding (TMRoPE):
- Decompose three-dimensional position information (time, height, width) into independent components and dynamically adapt to variable frame rates.
- In the OmniBench evaluation, this algorithm improved the accuracy of video understanding tasks by 12% and reduced the audio event positioning error to less than 8ms.
3. Streaming block processing and low-latency optimization
The model processes input in blocks of 2 seconds, combined with an incremental reasoning mechanism to achieve real-time interaction:
- The voice command response time is shortened to 0.3 seconds (the traditional model averages 1.2 seconds).
- On the SEED-zh dataset, the word error rate of streaming speech generation is only 1.42%, close to the level of human conversation.
AI Model Qwen 2.5 Omni
Performance: Benchmark and Industry Comparison
1. Omnimodal Task Evaluation
In the authoritative multimodal benchmark OmniBench, Qwen2.5-Omni-7B surpassed Google Gemini-1.5-Pro (200 billion parameters) with 7 billion parameters:
- Speech Understanding: Mandarin speech recognition WER (word error rate) is as low as 4.1%, better than Whisper-L (5.3%).
- Visual Reasoning: MMMU image question answering accuracy is 89.7%, an increase of 6.3% over ViLT.
- Cross-modal Fusion: Audio and video sentiment analysis accuracy is 92.1%, leading similar models by 8.7%.
2. Single-modal Special Capabilities
- Speech Recognition: CoVoST2 Chinese-English translation BLEU score is 29.4, close to the level of human translators.
- Image generation: DocVQA document visual question answering accuracy is 95.6%, surpassing LayoutLMv3.
- Mathematical reasoning: GSM8K’s problem-solving rate is 68.3%, only 3.2% behind GPT-4o (200 billion parameters).
3. Resource efficiency comparison
| Model | Parameter scale | Side deployment support | Speech generation delay |
| Qwen2.5-Omni-7B | 7 billion | Mobile/IoT devices | 0.3 seconds |
| Google Gemini-1.5 | 200 billion | Cloud only | 1.5 seconds |
| OpenAI GPT-4o | 200 billion | Cloud only | 0.8 seconds |
How does Qwen2.5-Omni-7B work?
Qwen2.5-Omni-7B is a large language model based on the Transformer architecture with 7 billion parameters. It uses a multi-layer self-attention mechanism and a feedforward neural network, and has strong language understanding and generation capabilities. The model is trained with massive text data (such as Internet pages, books, encyclopedias, etc.) to capture rich language patterns and knowledge.
When processing input, Qwen2.5-Omni-7B first tokenizes the text and encodes it into vectors, then understands the context through the self-attention mechanism and generates the corresponding output. The model learns the general features of the language through pre-training, and then fine-tunes it on specific tasks to meet the needs of different scenarios.
Qwen2.5-Omni-7B is widely used in natural language interaction, text creation, knowledge question and answer, and other fields, showing strong language processing capabilities. Its strong language understanding and generation capabilities enable it to handle complex language tasks and provide users with an accurate and smooth interactive experience.
How does Qwen2.5-Omni-7B work
Application scenarios and industrial implementation
1. Smart terminal devices
- Mobile deployment: The lightweight design of the model enables Qwen2.5-Omni-7B to run in real time on the Snapdragon 8 Gen3 chip, reducing power consumption by 40%.
- Home robot: Integrate visual SLAM and multimodal interaction to achieve environmental perception, sentiment analysis and proactive service.
2. Complex task scenarios
- Medical diagnosis: Fusion of CT images, electronic medical records and patient voice descriptions, assisting in the diagnosis of Parkinson’s disease with an accuracy rate of 89.2%.
- Educational technology: Real-time analysis of classroom videos, generation of personalized learning reports, covering 300+ teaching behavior tags.
3. Enterprise-level applications
- Intelligent customer service: Multimodal emotion recognition increases complaint handling satisfaction by 27%.
- Industrial quality inspection: Real-time detection of product defects through audio and video streams, with a missed detection rate of less than 0.5%.

Qwen2.5-Omni open source project AI model
Industry impact and ecological layout
1. Open source strategic value
- After following the Apache 2.0 protocol to open source, global developers have submitted more than 100,000 derivative models, covering 200+ industry scenarios.
- The number of downloads in the MoDa community has exceeded 2 million times, driving Alibaba Cloud AI service revenue to grow by 35%.
2. Competition and collaboration trends
- Closed-source model pressure: The open source of Qwen2.5-Omni-7B forces companies such as Google and Meta to accelerate the lightweight development of multimodal models.
- Hardware collaboration: Cooperate with Qualcomm and NVIDIA to optimize the chip NPU unit and further improve the edge-side inference speed.
3. Ethical and compliance challenges
- Multimodal data fusion has caused privacy disputes. The team has established cross-modal data fingerprint desensitization technology, which complies with international standards such as GDPR.
Future Development Direction
1. Modal Expansion
- Generation Capability Upgrade: Plan to support image and video generation within the year to achieve direct creation of “text→video”.
- Sensor Fusion: Explore access to LiDAR and millimeter-wave radar data to expand industrial and autonomous driving scenarios.
2. Cognitive Architecture Evolution
- Long-Term Memory Module: Develop a memory enhancement mechanism based on neuro-symbolism to support multiple rounds of complex dialogues.
- Multimodal Pre-training: Build a 10 trillion Token-level data set covering vertical fields such as medical and legal fields.
3. Industrial Ecosystem Construction
- Developer Platform: Launch Qwen Studio to provide low-code multimodal application building tools.
- Hardware Ecosystem: Cooperate with Xiaomi, OPPO and other manufacturers to pre-install the end-side AI service framework.
Conclusion
The release of Qwen2.5-Omni-7B marks the transition of multimodal AI from the laboratory to large-scale industrial applications. Its technological innovation, performance and open source ecology not only reconstruct the human-computer interaction paradigm, but also may bring exponential efficiency improvements to medical, education, industry and other fields.
With the expansion of modalities and the evolution of architecture, this model is expected to become the key infrastructure of general artificial intelligence (AGI).
About All AI Applications
AllAIApplications.com focuses on all AI applications, AI tools, global AI ideas and AI product advertising services. We are committed to AI technology research, AI idea exploration, using AI for business, AI for education, AI for cross-border e-commerce and other projects. If you have this idea, please contact us to discuss it together.
If you need to place AI ads on our website, or if you are a traditional smart watch manufacturer, you can also contact us at any time.

Qwen2.5 Omni
Alibaba Cloud Qwen2.5-Omni-7B FAQs
It is the first end-to-end full-modal large model released by Alibaba Cloud. It can process multiple inputs such as text, images, audio, and video at the same time, and generate text and natural voice responses in real time, simulating the human “receiving-thinking-expressing” process.
The Thinker-Talker dual-core architecture (simulating the human brain and vocal organs) and TMRoPE position encoding algorithm (solving audio and video synchronization problems) support multi-modal streaming interaction, and the response delay is as low as 0.3 seconds.
With 7 billion parameters, it surpassed Google Gemini-1.5-Pro (200 billion parameters) in the OmniBench benchmark, and the speech generation score reached 4.51 (close to the human level), and it supports end-side deployment (such as mobile phones and IoT devices).
Smart terminal: mobile phone voice assistant, home robot (environmental perception and emotion analysis).
Medical education: multimodal diagnosis (image + medical record + voice), classroom video analysis to generate learning reports.
Enterprise service: intelligent customer service (multimodal emotion recognition), industrial quality inspection (real-time defect detection).
It has been open sourced and follows the Apache 2.0 protocol. It can be downloaded through platforms such as Hugging Face, Moda Community, and GitHub. Developers can build industry applications based on it.
It is planned to support image and video generation, explore sensor fusion (such as LiDAR data), and promote the development of general artificial intelligence (AGI).
Traditional models are mostly single-link (such as ASR+NLP+TTS in series), while Qwen2.5-Omni natively supports multimodal input/output, and a single model can complete “seeing, listening, and writing”, which significantly improves efficiency.
The lightweight design enables it to run in real time on the Snapdragon 8 Gen3 chip, reducing power consumption by 40%, and supports scenarios such as voice command response and real-time translation.
More than 100,000 industry models have been derived, covering fields such as medical care and education, promoting the democratization of AI technology and lowering the threshold for enterprise innovation.
Achieving high performance with small parameters forces closed-source models to accelerate lightweight research and development, while cooperating with hardware manufacturers (such as Qualcomm and NVIDIA) to optimize end-side reasoning, forming the dual advantages of “technology + ecology”.



{kind=link}